Savings on Multi-Region API Migration with Serverless “API”
Case study how we migrated our API to serverless “API” with multi-region support saving money on the way.

Situation
We have a system that is responsible for maintaining complex relational data that is heavily used on one of the busiest air travel websites according to: similarweb. We had several iterations of redesigning this system using complex caching (multiple cache layers) and other optimisations (due to size of the documents) to achieve blazing fast response times for a better customer experience. This system and all the caching mechanisms were becoming cumbersome and affecting our flexibility. We were also getting huge spikes of requests at the time of cache invalidation that we had to deal with. We had to do something about it.
There are only two hard things in Computer Science: cache invalidation and naming things.
— Phil Karlton
Requirements
We wanted to create a system that would be:
- gracefully handling request spikes after cache invalidation,
- handling region failures,
- easy to extend and maintain,
- cheap,
- very responsive.
We knew that replicating the current solution in a multi-region solution would end up being costly, and the system would only become much more complex, and it still wouldn’t tick all the boxes.

Since we have a serverless first approach to designing our systems, we started thinking about how we could redesign this API to make it a hassle-free serverless solution that could be a low-cost solution targeting the multi-site active/active zone of above DR diagram.
Ideas
The API we've been working on uses highly relational data, so it's based on SQL. This makes data modelling super easy to understand and work with. Due to the nature of the data stored in the database, data updates are infrequent, but reads are very intensive.
The solution consisted of 2 APIs. One that was used to manipulate data and the other that exposed data to customers. Latter one was the system that was causing us so many problems.
After a quick analysis we found out that this API has a lot of dependencies. It supports multiple endpoints and query parameters. However, the cardinality of potential filter values is quite low. This characteristic gave us some ideas for redesign.

Solution
What if we could get rid of all those endpoints and… let’s say flatten all potential query parameters (with low cardinality) into pre-built documents that would go into the S3 bucket exposed through CloudFront?
That way we can:
- easily do cross-region replication,
- easily handle cache invalidations because documents are cached and invalidated using CloudFront,
- serve from multiple regions and handle region failures gracefully using e.g. OriginGroups.
We have estimated to have >60k different “responses”. Seems like not that much after all.
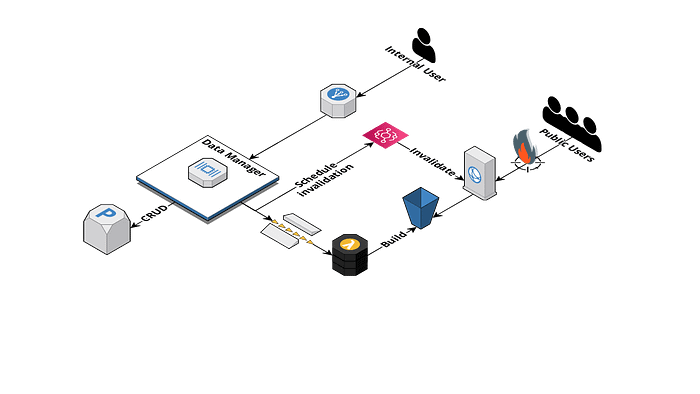
Delivery
Sounds great, but there is one caveat. We have to do some changes on all consumers of our APIs.
What are potential options here?
- Redirect using Lambda@Edge — fast & easy delivery, extra cost
- Process data using S3 Object Lambdas — very flexible, but requires some effort for writing filtering logic on read and it will increase cost of solution
- Just change everything on all clients — the most painful solution, but it will guarantee that there won’t be any leftovers and patches left behind
Here is a moment of regret. We chose the last option because we have had bad experiences with migrations where we had to support backward-compatible, outdated solutions because “it works”.
Do I regret choosing this option? Yes, as it took a lot of nerve to get it delivered as many teams had to coordinate and fit it into their backlog. If I could go back in time, I would definitely choose the Lambda@Edge option.
Would I consider that solution “delivered delivered”? No. I still would have to track and monitor APIs that still were not migrated to the new resource paths.
Results
We are very happy with our current solution. It is super easy to maintain, extend and test. Some hacks with scaling servers before cache invalidation? Gone. Multi-region support? Check. Billing? Down. Seeing your bills go down after adding multi-region support is really good news.
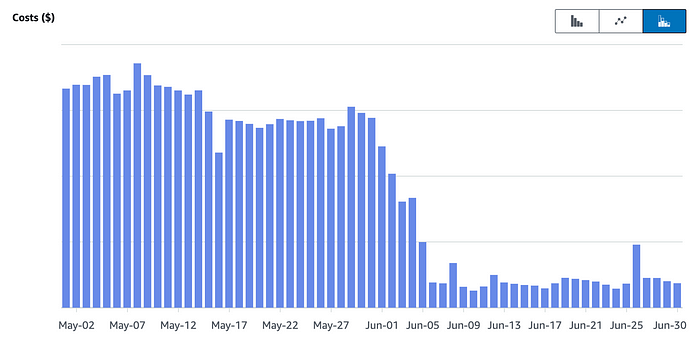
Does it mean I should migrate my API that way?
‘It depends’ is almost always the right answer in any big question.
- Linus Torvalds
So… it depends. On your requirements, your system, your plans and how dynamic your data is. It won’t work well in case of very frequent data modifications and near realtime requirement. Also in case of super high cardinality of filter parameters it might be better to try to go for S3 Object Lambdas instead of building docs on modification.
Summary
This redesign helped us simplify our architecture and improved many system characteristics. We have plans to apply that pattern to another applications in our portfolio (if applicable). Unfortunately it’s not a silver bullet so let’s summarize it.
Pros:
- Saving money
- No brainer multi-region support
- Easy handling request spikes after invalidation
- Super simple infrastructure
- Easy caching with ETag support
- Versioning
Cons:
- Manually documenting resources with Open API
- Migration
- Applicable to limited set of systems with infrequent data modifications and low caching cardinality
