How to NOT miss Cloudwatch Alarms

Motivation
Dashboards
Dashboards are great for getting an overview of systems health, performance, KPIs and current situation in your workloads in general. Everyone knows that and there is no doubt that they are necessary. The only problem with dashboards is that usually you have so many resources and projects in the cloud that amount of dashboards and metrics to observe is increasing so quickly that it’s unbearable, or even impossible, to put into a single or multiple views. So it’s not a good solution to support systems in a big organisations — especially if you will take into account multiple environments that you’re running.
Alarms
Great solution for that are alarms. You want to focus only on a pain-points and react on them ASAP. In my opinion best practice is to resolve them automatically whenever it’s possible. For example by setting up autoscaling on your resource, resharding your Kinesis stream or having automated process for handling messages in the DLQs.
In many cases it’s hard to automate failure handling that we are getting alarmed on. For example you might start receiving malformed events in your event-based system or you might getting errors due to 3rd party being down (which is out of your control) and only thing you have in place is your circuit breaker. It can ease the pain, but your system is not working as expected and it will trigger one of your alarms, hopefully.
There is one threat though when it comes to alarms. You are getting alarm whenever there is a CHANGE in the alarm state. Let’s imagine scenario that your alarm got triggered and it was unnoticed (I know, it won’t happen to you). Since then it’s all the time in ALARM state for a long time. You won’t find out about that until it will trigger another alarm or you will spot information about it in your logs, dashboard or it will be reported by your QA team or what is worse — customers.
Solution
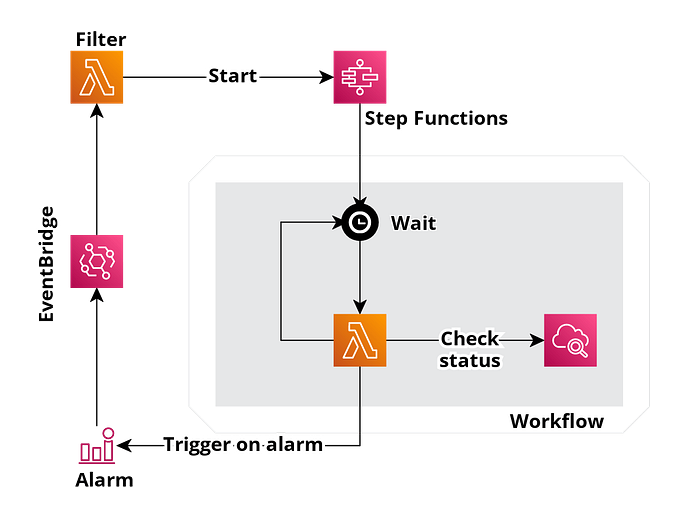
Repeating alarm notifications in case they are not resolved within defined time period sounds like a great idea. After quick research you can find article with ready solution by AWS Labs that sounds like a great solution for that problem.
Which looks like this on diagram:

I have deployed it quickly to my dev environment and have found out that it has couple of caveats and it’s not exactly what I was looking for. It was a great base for getting started, yet I decided to tweak that solution a little bit.
What can be improved?
- Autoscaling
All alarms are triggering StepFunctions workflow. ALL OF THEM. It means that it gets triggered by every autoscaling alarm. In case of accounts which has lots of autoscaling resources it might pile up. - Tag-based filtering
There is tag-based filtering built into solution which disables checking state of alarms if they are not tagged properly — and that’s great. Unfortunately if your alarm (with proper tagging disabling the process) is triggered it still starts StepFunctions workflow first and after wait period it check tags. - Repeated alarm payload.
When your Cloudwatch alarm is triggered AWS puts information about its configuration and why it got triggered into notification that is published to your SNS topic. Issue here is that payload that is sent automatically by AWS is different than one that is sent during repeating alarm process. It’s a big issue in case you have process in place that does something based on that notification payload. You might generate CTAs (CTA — Call To Action), visualise state of the metrics that are part of triggered alarm or do any other thing with lambda consumer. I guess this is not made up case as there are already folks facing this issue.
There is already open issue on github about that scenario:
What actually is that payload difference?
It depends on the case.
Single dimension alarm
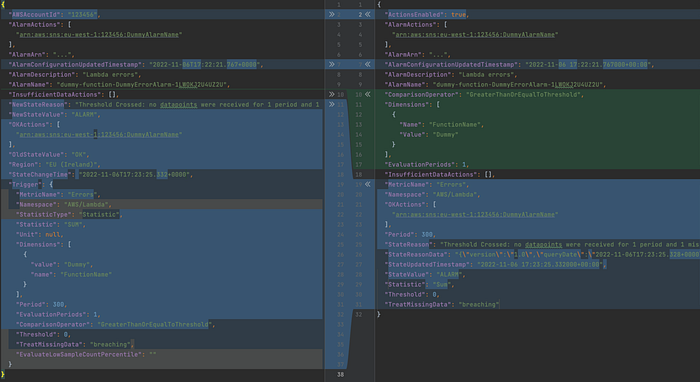
Calculated metric alarm
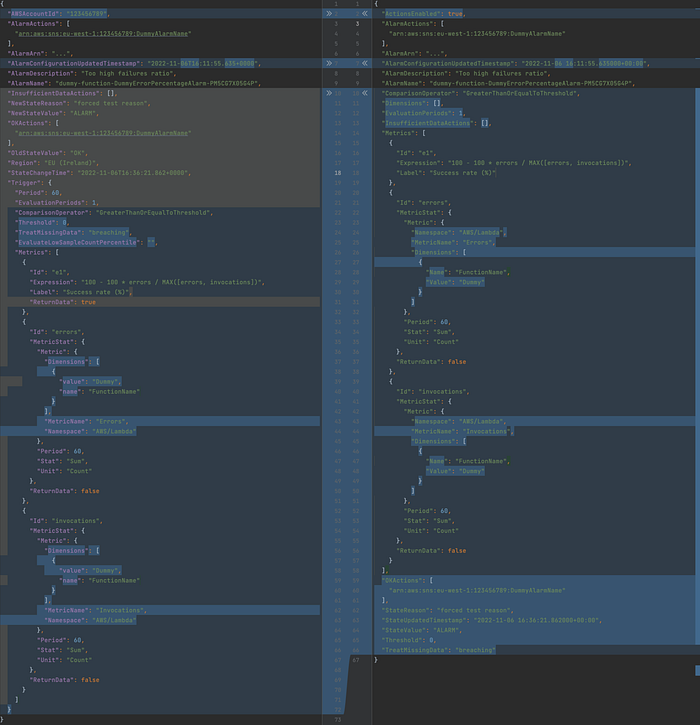
Composite metric alarm
During testing of model change in payloads I have found out that there is a bug. Every time composite alarm is triggered StepFunction workflow ends up with exception.

First just try to spot an issue in this part of code:
Why it fails? There is a Cloudwatch SDK describe_alarms method called with alarm name only. If it’s called that way it will never return CompositeAlarms. In that case it’s mandatory to add all required AlarmTypes to the list according to documentation. Since solution assumes handling of CompositeAlarms behind if statement, it will fail with attached error.
I have opened PR with quick fix: https://github.com/aws-samples/amazon-cloudwatch-alarms-repeated-notification-cdk/pull/7
How we can improve that solution?
Autoscaling alarms issue
Lambda consumer that is triggered by EventBridge is doing best effort to filter out scaling based actions before starting StepFunctions Workflow.
Tag-based filtering issue
Lambda consumer that is triggered by EventBridge is checking triggered alarm tags before starting StepFunctions Workflow.
I think that it’s better to have opt-out instead of opt-in policy in this solution. Alarms always should be addressed and we don’t want to miss them by default. Especially in case someone would like to add alarms repeater to their already existing infrastructure with multiple alarms defined. That way we can use new mechanism without retagging all resources.
Repeated alarm payload issue
I would like to limit the amount of effort into maintenance on this one. In AWS Labs solution payload sent to SNS was either MetricAlarm or CompositeAlarm that was taken from Cloudwatch DescribeAlarms API, but as we saw above it’s not good approach. Since it will require cobbling together payload out of informations from multiple data sources (as we don’t have all necessary data in alarm details) we have to find another solution.
Idea 1: It seems easier to use CloudwatchSetAlarmState API with special reason that will make clear that alarm was repeated. It seems like a better solution as we can just reset alarm by setting it to OK and back to ALARM state immediately and just rely on AWS mechanism of delivering notification. This approach have some drawbacks though.
- There might be OKActions defined that we will trigger,
- it can obscure information for how long our alarm remained in the ALARM state,
- we have handle specially retriggered alarm to not run step functions workflow again.
I don’t like that… a lot.
Idea 2: There is an API in Cloudwatch DescribeAlarmHistory where we can get exact message that was sent to SNS and that’s lovely. It requires to filter out OK notifications, picking last sent notification for each alarm action defined in alarm. What is more — model of the data is not easy to work with, as it lacks types, but at least it feels like a right solution.
I decided to use SetAlarmState approach only as a last resort in case that publishing on SNS fails or we will face any unexpected issue.
Where I can find it?
Solution is available on github and it’s based on the SAM instead of CDK.
I am going to open PR to awslabs repo with the same solution I did in my repo, but adjusted to their style. I think it will be better for the community thanks to the article on AWS blog and populatity of awslabs repos. If you think that’s great idea, you can motivate me with the claps or comments on this article.
Summary
Repeating alarms is really useful mechanism and I wonder why it’s not something that could be just turned on in the account/organization as an extra feature without putting your own solution in place.
I know that setting up alarms in the AWS might be sometimes tricky when it comes to setting up proper thresholds on every alarm. Especially that you don’t want to get false-positive alarms or get informed too eagerly about issues when you have already built mechanism to gracefully handle them. What is more you have to rethink settings for development and production accounts as they have way different characteristics.
I think that it’s not a task, but more like a journey. Using repeating alarms approach can make it easier. It will remind you you and your teammates about setting misconfigured alarms properly and prevent you from not noticing alarm. I know that you have never skipped dev account alert notification or have deleted dev account alert e-mail, but some people done that many times because: they just got used to them, “they have more important things to do” or keep forgetting about them… so maybe let’s remember them every X seconds.
