Elasticache Serverless — is it bad or just not for you?

TL;DR; I am going through the features, and why those might be great for some companies and then I am comparing pricing to the non-serverless version, and finally I am doing a small comparison to the serverless competitor — Momento.
Features summary:
First of all, let’s start with presenting the service itself.
- No capacity management
- Pay-per-use
- 99.99% SLA
- Storage: from 1GB — 5 TB of storage
- Built-in throttling with limits for storage and ECPUs (ElastiCache Processing Units) per second according to: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-elasticache-serverlesscache-cacheusagelimits.html
- Encryption is always on (at rest/in transit/backups)
- Single endpoint
- Up to millions of TPS
Notes:
- Requires VPC
Pricing
According to pricing it’s priced only based on (eu-west-1 rates):
- Data stored: 0.14$ / GB-Hour rounded by ceil to next value (since data stored is billed in full GBs it means that minimum pricing is 90$/month)
- ElastiCache Processing Units: $0.0038 / million ECPu (which are equivalents of KB of data transferred) so simplifying $0.0038 / GB
I have created a simple gist that you can use for checking the potential cost of your existing Elasticache cluster here. Just replace $YOUR_CLUSTER_GB_SIZE, $YOUR_CLUSTER_NAME and $YOUR_REGION and add rows for each node in your cluster.
{
"metrics": [
[ { "expression": "pricestorage+(ecpus/1000000*0.0038)", "label": "Serverless Elasticache Pricing", "id": "price", "yAxis": "right" } ],
[ { "expression": "SUM(METRICS())/1000", "label": "ECPus", "id": "ecpus" } ],
[ { "expression": "$YOUR_CLUSTER_GB_SIZE*0.14*24*30", "label": "PriceStorage", "id": "pricestorage", "yAxis": "right", "visible": false } ],
[ "AWS/ElastiCache", "NetworkBytesOut", "CacheClusterId", "$YOUR_CLUSTER_NAME-001", "CacheNodeId", "0001", { "region": "$YOUR_REGION", "id": "m1", "visible": false } ],
[ "...", "$YOUR_CLUSTER_NAME-002", ".", ".", { "region": "$YOUR_REGION", "id": "m2", "visible": false } ],
[ "...", "$YOUR_CLUSTER_NAME-003", ".", ".", { "region": "$YOUR_REGION", "id": "m3", "visible": false } ],
[ ".", "NetworkBytesIn", ".", "$YOUR_CLUSTER_NAME-001", ".", ".", { "region": "$YOUR_REGION", "id": "m4", "visible": false } ],
[ "...", "$YOUR_CLUSTER_NAME-002", ".", ".", { "region": "$YOUR_REGION", "id": "m5", "visible": false } ],
[ "...", "$YOUR_CLUSTER_NAME-003", ".", ".", { "region": "$YOUR_REGION", "id": "m6", "visible": false } ]
],
"region": "$YOUR_REGION",
"title": "Elasticsearch Serverlss ECPus & pricing",
"stat": "Sum",
"view": "timeSeries",
"period": 86400
}Popular claims
Storage is very expensive
What people are missing here? It’s not EBS storage. It’s a quick access memory in multiple AZs with high availability guarantees and single-digit millisecond latency.
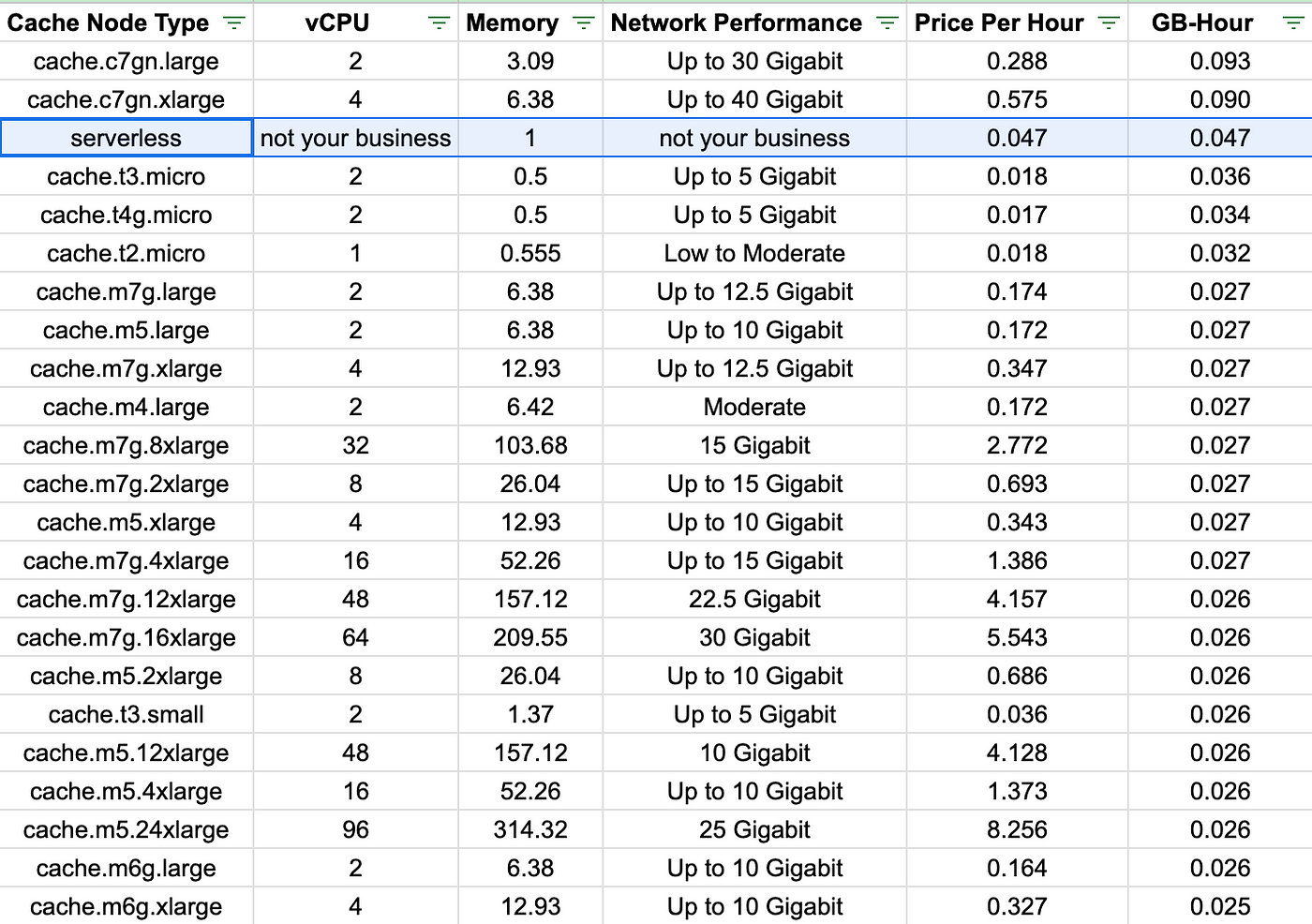
Let’s look at the pricing of Elasticache nodes (here) and translate it to Serverless pricing. Since it’s out-of-the-box highly available it means that it’s $0.14/<amount_of_AZs>. Assuming that you are using 3 AZs we can approximate its cost to look like on the screen below where instance types are sorted in descending order by GB-Hour.
It is one of the most expensive configurations and it’s based on the on-demand pricing. In the case of reserved instances, it will be even more expensive.
What people are also missing in this context is…
Storage scaling
It is not a straightforward topic in the Redis world. It depends on whether you are using replication or cluster topology (more details here).
Cluster mode disabled
Since instance size is your maximum storage in the whole cluster, it means that change of data stored will push you to up-scale your instances (so usually 2x cost for 2x size).
Cluster mode enabled
Your data will be sharded. In case your data is not replicated into multiple nodes in shards, then it means that in case of a node failure, you will lose data, and usually you will have to pay for them multiple times. Apart from that your implementation will be more complicated (not working like in a single-endpoint solution) and not all operators will be available (MGET, MSET).
This brings us to…
High availability
Achieving high availability with scaling is not super trivial. Many times I’ve seen Redis clients that were not using all read nodes (so full cluster potential) and just burning money.
Elasticache serverless scales vertically and horizontally based on memory, CPU, and network. Exposes a single endpoint that works as a proxy (written in Rust for leveraging memory & concurrency safety) with load balancing that you don’t even have to care about. This proxy also picks up local availability zones to minimize latency. All you need is to turn on SSL and read from the replica option.

Where it is especially interesting?
Memcached high availability
I have no experience in using Memcached (I admit it, I am a Redis fanboy), but the new features introduced seem exciting for Memcached users. Why? Supporting high availability for Memcached is not trivial. You can read more about it here.

Summary
What I think is great about this service is that AWS now can take heavy lifting from customers and let developers focus on the business and building products that drive it. That’s the beauty of cloud services.
Achieving high availability might be a big issue for some teams and that might impact time-to-market which might be worth this few extra bucks and be ahead of the competition. For skilled teams, it might feel like a waste of money. At least now architects have this trade-off.
I have calculated the cost of one of my bigger clusters which has huge traffic, but not that big data set and not that big objects in it. Pricing is very similar to what I would pay with cluster-provisioned on-demand nodes.
Do I pay that amount for it? No, as I am using reserved nodes.
Do I have to scale & monitor it? Yes.
Did I have to make some tweaks in clients to use the whole cluster potential? Yes.
Is it worth it? Do the math and consider those trade-offs yourself. I don’t think that this service is overpriced. I’ve read opinions that “it will cost at least $90 and that’s expensive” or “Let’s better use DynamoDB for caching”.
Well… in guinea pig projects/low traffic projects — yes, but it’s not true on an enterprise scale. Using DynamoDB for caching in those types of systems is far from optimal and those few hundred dollars might be worth avoiding risks and getting a competitive edge.
Where do I think it can shine? In really super high-traffic services with the relatively small size of a cache.
What could be done better?
- Fixing minimum $90/month issue or…
- Price based on more granular storage unit than 1GB
- Global Support (I guess in the future)
- It could be cheaper
If you don’t like it you also can consider…
Serverless alternative
Momento looks like a solid alternative for serverless caching with the support of millions of TPS (those are not my words, but the CEO of Momento) on their “Pay per use” pricing tier. It’s priced per data used at $0.5/GB.

Sounds great and it’s fully serverless according to the famous Litmus Test for Serverless.

Serverless on an enterprise scale
I wrote previously about enterprise scale.
So how does Momento compare to Elasticache Serverless on a high-traffic application?
Momento pricing states that it costs $0.5/GB of data transferred and in Elasticache Serverless it’s only $0.0038/GB.
First, let’s take a look at price comparison on a low throughput system.

Here is price comparison on a bigger scale where results changes a bit.


If you are interested in finding that breaking point you can use Wolfram Alpha — here is an example for 8GB.
Bye
I know it was a quite long article, so if you read it up until here, thank you for your time. Please let me know what you think about this one and please reach out if I made some calculation mistakes here.